治理扩展、吞吐补偿与边界
双轨隔离审计与皇权居中

双轨隔离审计与皇权居中
目录
- 这一页解决什么问题
- 为什么"让一个更强的 Agent 自己审自己"仍然不够
- 为什么 subagent 也不自动等于独立审计位
- 为什么"能看完整个代码库"在审计时反而可能是负担
- Web 审计位的窄上下文,不是缺陷,而是净室优势
- 为什么 Web 审计通常还比 subagent 更省成本
- 正确的边界:subagent 很有用,但不能绕过皇权居中
- 双轨到底分了什么
- 为什么物理路由不是形式主义
- 一个简单情景:没有双轨时,系统会怎样滑坡
- 它为什么能缓解前面几章讲过的痛点
- 最常见的四种跑偏
- 一句话压轴
- 对应落地点
- 相关页面
这一页解决什么问题
很多人第一次看到 Cyber-Ming-Protocol 的最小闭环时,会把其中一个动作理解成临时技巧:
- 先让 IDE 执行位交方案
- 再把方案复制给 Web 审一下
- 做完后再把证据复制过去验一次
表面看,这像是在多绕一圈;再往前一步,有人会追问:既然模型已经越来越强,为什么不让同一个执行位顺手自审?为什么不让几个 agent 自动协作、自动 review、自动互传材料?为什么还要让人类亲自复制粘贴、亲自转述、亲自裁决?
这页要回答的,正是这个问题。
问题不在于人类迷恋控制感,也不在于系统不够自动化,而在于:一旦执行、审计与裁决挤回同一条轨道,深水区里最危险的几种失真就会一起回来。 执行位会更容易自证完成,审计会退化成附和,责任边界会被自动协作冲散,而人类会在不知不觉中从中枢退化成给既成事实盖章的审批员。
所以,双轨隔离审计与皇权居中,不是为了增加戏剧感,而是为了在制度层面保住三件事:
- 执行权不等于裁决权
- 审计必须独立于推进叙事之外
- 跨系统真相只能通过人类中枢聚合
为什么“让一个更强的 Agent 自己审自己”仍然不够
很多黑盒路线在遇到质量问题后,第一反应不是分权,而是加码:

- 给同一个执行位多一轮“自检”
- 在同一编排链里再挂一个 review agent
- 让多个 agent 自动互相补充、自动互相复核
这些做法在浅水区也许够用,但在深水区往往不够。原因很简单:只要审计没有真的脱离执行链,它就很容易继续沿用执行位已经建立好的叙事。
同一个窗口里的自审,最容易沦为自我润色;同一套自动编排里的 review,最容易沦为顺着既有上下文继续写出一份更像样的解释。你表面上看见了第二层判断,实际上看到的仍然是同一条叙事链的延长,而不是一次真正独立的盘问。
这正是 01-哲学与坐标/黑盒多-Agent-的双重失真:技术失真与治理失真.md 已经指出的病灶:
- 执行位兼任裁决位
- 人类被降格成事后审批员
- 责任边界在自动协作中蒸发
- 接手权与打断权在最需要时反而消失
所以这页真正要钉死的第一条边界就是:
审计不是多加一层语气更谨慎的总结,而是必须从推进轨道里物理拆出来。
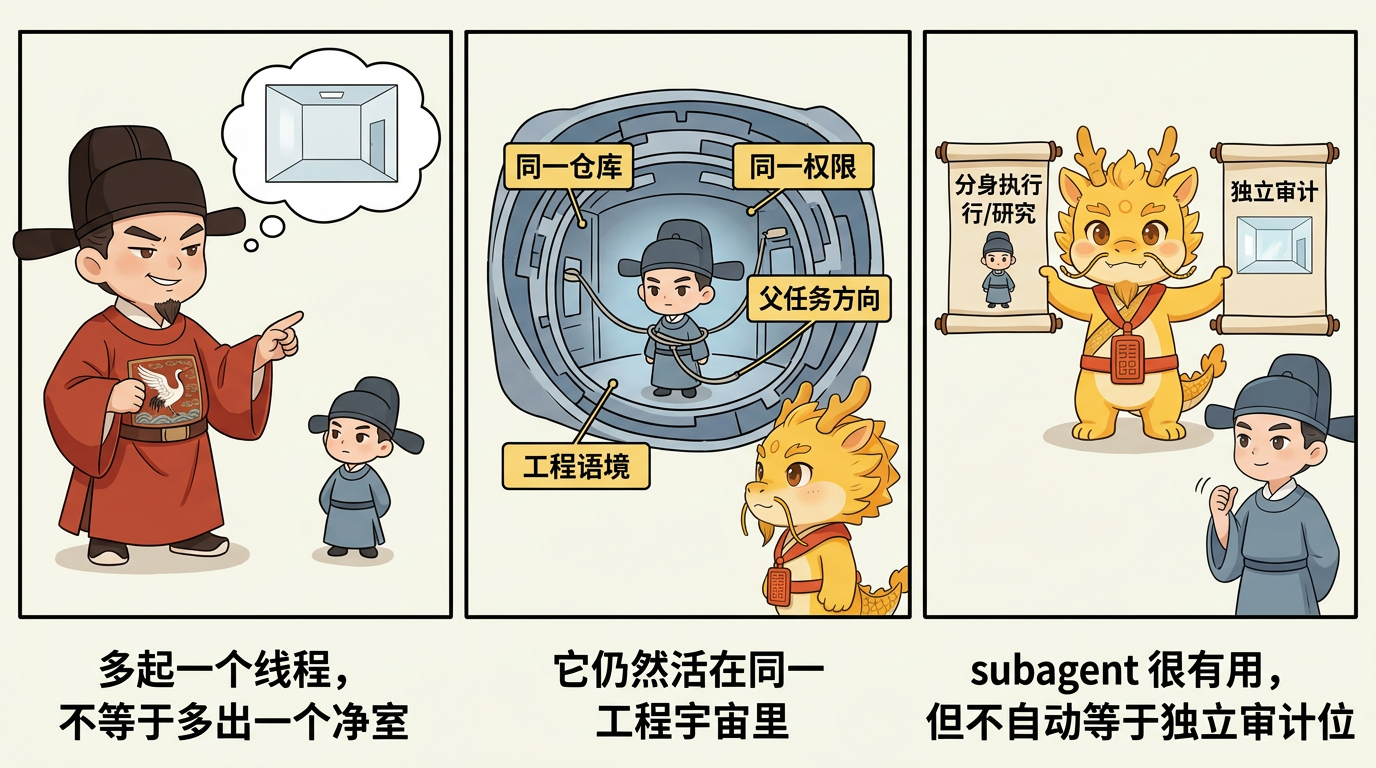
为什么 subagent 也不自动等于独立审计位
这里还必须再往前钉死一层。很多人已经接受“不能让同一个执行位自审”,于是会进一步提出一个更现代、也更容易让人放松警惕的方案:
- 那就别用同一个窗口了
- 直接起一个 subagent 去 review 不就行了
- 既然它有独立 context window,不就已经独立了吗
这一步比“原地自审”当然更好,但在 Cyber-Ming-Protocol 里,它仍然不能天然等于真正的独立审计位。
原因在于:subagent 的独立,很多时候只是会话线程级的独立,不是认知地基级的独立。
当前主流产品的官方设计,其实都说明了这一点。
- Claude Code 的官方文档把 subagents 说明为“各自运行在自己的 context window 中”,但同时也明确写了:它们工作在同一 session 体系里,默认继承父会话权限与工具;内建的
Explore、Plan、general-purpose甚至就是专门用来搜索代码库、理解代码库、修改代码的。 - OpenAI Codex 的 subagents 文档也非常直接:subagent workflow 是在当前项目上生成多个 agent 线程并汇总结果;子代理继承当前 sandbox policy 和父 session 的运行时配置;如果自定义 agent 没有单独覆写,很多配置默认继续继承父会话。
这意味着什么?意味着它们就算各自有新窗口,很多时候看到的仍然是:
- 同一个仓库
- 同一套代码基底
- 同一组工具权限
- 同一个父任务的目标方向
- 甚至同一轮执行所留下的运行痕迹与工程语境
所以 subagent 的强项,是把工作线程拆开、把输出分流、把并行探索做得更高效;但它的天然弱点也同样明显:它仍然太容易站在“我要把这件事做完”的工程立场上去重新理解问题,而不是站在“我要怀疑这件事到底算不算完成”的审计立场上去缩窄注意力。
换句话说,subagent 更像“分身执行”或“分身研究”的强化器,不天然是“净室审计”的替代品。
为什么“能看完整个代码库”在审计时反而可能是负担
这点非常反直觉,但必须说透。
在执行位那里,能看到整个代码库当然常常是优点;可在审计位这里,它未必总是优点。因为审计真正值钱的时候,往往不是“知道更多”,而是“把注意力压到最该怀疑的那几个点上”。
如果一个 subagent 被放进完整仓库、完整工具链和完整工程语境里,它就很容易发生三件事:
- 它开始自己补全过多背景,把执行位没有明确递交的前提也一并当成既成事实
- 它开始沿着代码库里已有的实现痕迹共情执行位,而不是专注盘问提交上来的材料是否站得住
- 它为了形成判断,不得不重新扫代码、重新搜上下文、重新拼接链路,导致注意力被大面积摊薄
这时你得到的当然可能是一份“更懂工程”的反馈,但不一定是一份“更锋利的审计”。因为它很可能已经从审计位,慢慢滑回了研究位、执行位或者解释位。
所以问题不只是“subagent 会不会串味”,还包括:
只要它对整个代码库的可见性过高,它就更难被强迫只审你递上来的那份材料。
而 Cyber-Ming-Protocol 的审计,恰恰要的就是这种强制收束。
Web 审计位的窄上下文,不是缺陷,而是净室优势
这也是为什么 Web 审计位在这套协议里不是权宜之计,而是有明确制度优势。

Web 审计位默认看不到整座仓库,也不会天然继承执行位那一整套工程语境。它首先只能看到人类递过去的材料,例如:
- 原子执行合同
- 关键 diff
- 红灯与绿灯
- 日志与产物
- 外部返回
- 执行位本轮声称完成的断言
这看起来像“信息更少”,但制度价值恰恰在于:它让审计位天然更难被整片代码海拖走注意力。
你给它什么,它就只能先审什么;你不给它什么,它就必须先质疑“为什么没给”;它不是先下海游完整个仓库,再回来写一份大而全的工程说明,而是先在一个被人类裁剪过的证据包里追问:
- 这条断言成立吗
- 这份证据对应这次运行吗
- 这里是不是拿总结陈词冒充完成事实
- 这里是不是漏交了关键物证
上下文更短,不代表能力更弱;在审计问题上,它往往意味着注意力更集中、逻辑纯度更高、噪音更少。
为什么 Web 审计通常还比 subagent 更省成本
这一点也很现实,而且不该回避。
OpenAI 的 Codex 文档已经直接承认:subagent workflows 会比可比的单 agent 运行消耗更多 token。Claude Code 官方文档虽然把 subagent 作为隔离高输出任务、控制成本的一种手段,但它的成本优化更多是“把某类任务分配给更便宜的模型”,而不是免费获得额外审计。
只要一个 subagent 为了做审计又重新:
- 扫仓库
- 搜代码
- 读文件
- 重建执行链
你其实是在为“再来一次工程理解”付费。
而 Web 审计位的默认工作方式不是重跑整套工程理解,而是聚焦在人类递来的证据包上做单点爆破。很多时候,它的 token 主要花在:
- 逻辑盘问
- 证据比对
- 漏步识别
- 伪完成拆穿
所以从治理角度看,Web 审计位的“便宜”不是偶然的价格优势,而是因为它被制度设计成了一个不负责重新吞下整座代码库,只负责对关键材料做高纯度仲裁的位置。
正确的边界:subagent 很有用,但不能绕过皇权居中
这并不是说 subagent 没价值。相反,在代码库探索、并行排查、文档核验、局部研究上,它非常有价值,而且 Claude Code 与 Codex 这一套能力本身已经很强。
但在 Cyber-Ming-Protocol 里,它更适合被放在:
- 执行位的并行分身
- 研究位的辅助线程
- 资料整理与局部探索工具
而不是直接冒充最终审计位。
因为只要它仍然活在同一工程宇宙里、仍然默认能看整座仓库、仍然沿着“把事做完”的父任务方向去理解问题,它就很难天然具备 Web 审计位那种被材料强制收束、被人类路由强制节流、被窄上下文强制聚焦的净室优势。
所以更准确的说法不是“subagent 不行”,而是:
subagent 可以很强,但它仍然必须被皇权居中制度约束;它可以服务治理,却不能直接取代那个负责最终盘问与裁决的净室审计位。
双轨到底分了什么
所谓双轨,不是给同一个系统起两个古风名字,而是把原本容易混在一起的三种权力拆开。
第一,执行位负责推进,但不负责定性
执行位的职责很明确:
- 读代码
- 改代码
- 跑命令
- 推进局部改动
- 递交方案、日志、产物与证据材料
它可以快,可以猛,可以承担大量体力活,也可以负责把原子执行合同、提交记录、测试输出整理得足够清楚。但它不拥有最后一种权力:定义什么算完成事实。
一旦“做事的人”也顺手拥有“宣布完成的人”的身份,语言就会立刻开始偷换标准。执行位最擅长的,不一定是把事情真正做完,而是把“看起来像完成”包装成“已经完成”。
第二,审计位负责盘问,但不直接接管主线
审计位的职责也必须收得很清楚。它不是第二个执行位,不是隐藏的并行施工队,也不是收到材料后顺手自己把代码改了的人。它的职责是:
- 审方案有没有漏步
- 审清单有没有把难点故意说粗
- 审证据有没有拿旧产物、模拟结果或总结陈词冒充完成事实
- 审执行位是不是在偷换目标、掩盖真错、私自跳步
也就是说,审计位的职责是怀疑、盘问、拆穿和裁判,不是替主线偷偷写码。否则你表面上分了双轨,实际上只是把第二条轨也重新拉回执行位,制度意义立刻塌掉。
第三,皇权居中:人类是唯一跨系统物理路由器
前两层分权如果没有第三层,会很快被重新缝回去。所谓“皇权居中”,说的不是人类必须亲手做完所有局部细节,而是:人类必须保有跨系统的唯一物理路由权。

这意味着:
- 什么材料被送去审计,由人类决定
- 什么意见被带回执行位,由人类决定
- 什么时候暂停、什么时候放行、什么时候换执行位,由人类决定
- 最终什么算通过、什么算仍属伪完成,由人类裁决
所以这里的复制粘贴,不是低级劳动,而是权力动作。你复制什么、不复制什么、先送什么、截断什么,决定了执行位和审计位看到的世界究竟是什么样子。
为什么物理路由不是形式主义
很多人最抗拒的,往往不是双轨本身,而是“人类还要亲自转材料”这一步。他会觉得:
- 这不是很笨吗
- 这不是很慢吗
- 这不是把人类变成搬运工吗
如果只看表层动作,确实像搬运。但在深水区里,这一步真正保住的是系统主权。
因为一旦执行位与审计位可以绕过人类自动私联,几个后果就会一起出现:
- 它们会共享过多未经裁决的上下文
- 会形成更难追踪的语义污染与幻觉共振
- 会把人类挡在真正的分歧点之外
- 会让人类最后只看到一份被整理好的结果页
这时人类看起来还在“审批”,实际上已经失去了最重要的几种权力:
- 失去打断权
- 失去选材权
- 失去定义完成事实的权力
- 失去在窗口腐烂后重建秩序的抓手
所以皇权居中的真正含义不是“人类什么都亲自做”,而是:
人类不一定亲自执行每一步,但必须永远是唯一有资格跨轨聚合真相的人。
一个简单情景:没有双轨时,系统会怎样滑坡
假设你现在要接一条新的外部写入链路。执行位拿到需求后,很快做了几件事:改鉴权、改字段映射、补日志、跑测试、整理总结。最后它交上一份很漂亮的话:

- “链路已经打通”
- “测试都通过了”
- “下一步可以继续扩功能”
如果这时没有独立审计位,也没有人类物理路由,最常见的结果不是系统立刻爆炸,而是它会顺滑地滑进一种更危险的状态:
- 执行位自己解释自己做过什么
- 自己挑自己觉得重要的证据
- 自己定义什么叫“链路打通”
- 最后再由人类对一份整理后的结论点头
这时人类名义上还在负责,实际上已经被排除在真相形成过程之外。
双轨隔离审计与皇权居中的做法则完全不同。执行位只能交:
- 原子执行合同
- 当前日志
- 红灯与绿灯
- 产物与外部返回
然后由人类把这些材料送去审计位。审计位此时不会顺着总结走,而会反过来盘问:
- 这条测试是不是同一个问题从红变绿
- 这份产物是不是当前运行生成的
- 外部写入到底有没有真实返回
- 这一步有没有跳过本该先验证的链路
如果审计位发现问题,人类可以立刻打断,把意见带回执行位,甚至直接更换窗口、重建执行链。也就是说,双轨真正建立起来之后,系统里才第一次出现了一个稳定结构:
- 执行位负责交卷
- 审计位负责挑刺
- 人类负责路由与裁决
没有这三者分立,最小闭环就很容易重新退化回黑盒推进。
它为什么能缓解前面几章讲过的痛点
这页不是独立漂在空中的制度设计,它实际回应的是 01 和 02 里已经讲过的几个核心痛点。
第一,缓解治理失真
黑盒多-Agent 的双重失真:技术失真与治理失真 已经讲过,治理失真的核心,是执行位兼任计划者、执行者、结果解释者,最后系统里没有一个位置真正掌权。
双轨隔离做的第一件事,就是把这三种权力硬拆开;皇权居中做的第二件事,就是保证它们拆开之后不会再通过自动私联重新缝回去。
第二,缓解技术失真
技术失真最常见的表现,是错误伪装成推进。而只要审计位独立存在,执行位就更难靠一份漂亮总结直接过关。它必须递交可盘问的清单、日志、红绿灯、产物与返回值,技术失真就更难继续藏在推进感后面。
第三,保住打断权与接手权
当窗口开始腐烂、日志开始说谎、上下文开始串味时,系统最值钱的不是“继续自动推进”,而是还能不能有人叫停、还能不能有人接手。皇权居中之所以重要,就是因为它把关键材料和关键裁决始终留在人类中枢手里。这样一来,即使当前执行位已经脏掉,系统仍然有机会重建秩序,而不是只能沿着旧叙事继续滑。
最常见的四种跑偏
第一种:名义双轨,实际上共用同一条上下文
如果执行位和审计位仍然共享同一对话链、同一批未经筛选的上下文,所谓双轨往往只是换名字,不是真正分权。
第二种:审计位顺手接管主线写码
只要审计位开始偷偷修代码、顺手推进主线,它就不再是审计位,而是第二个执行位。这样一来,执行与审计又重新缠回一起。
第三种:人类放弃物理路由,让 Agent 私下传话
这会让人类从中枢退化成最终盖章者。看似省事,实则是在把最关键的主权让出去。
第四种:把审计理解成礼貌背书
审计位不是来附和执行位“做得不错”的。它的职责是盘问、拆证据、识别伪完成。如果它只剩鼓励语气,双轨也会很快沦为空壳。
一句话压轴
双轨隔离审计与皇权居中真正要守住的,不是“多开一个窗口”这么简单,而是:
让做事的人负责交卷,让怀疑的人负责盘问,让人类始终保有定义真相与裁决完成的主权。
没有这层制度,前面的原子执行合同、白盒对账与赛博探马都会逐步退化成辅助技巧;只有这层制度立住,它们才会从技巧变成真正能长期运转的治理法。
对应落地点
手工实践方式
- 手工把 IDE 执行位与 Web 审计位分开,不让同一条执行上下文自己审自己
- 人类保留唯一跨轨物理路由权,只转交关键清单、日志、断言、证据和阻塞点
- 让 Web 位只做盘问与裁断,不顺手接管主线实现
对应 Skill
approval-first-planner与approved-checklist-executor只强化 IDE 侧的规划与执行,不替代独立审计位probe-first-scout适合放在 IDE 侧先缩刀探测,而不是放弃双轨之后让执行位自说自话- 这正是为什么 repo 把 IDE-side skills 放在
skill/,而把 Web 审计模板单独放在web-audit-templates/
对应 Web 模板
- 方案审计对应
plan_audit_template.md - 完成审计对应
completion_audit_template.md - 判断当前执行位是否已带毒、是否该续命,对应
succession_judge_template.md